
GOSS Ph3 PROSERA Readout
I'm a bit skeptical

This has been getting some attention here into Feb, and rightly so, as it’s probably a +200%/-90% binary event, give or take! I lean negative based on the total body of evidence. Obviously, we’ll find out for sure in a couple of weeks or so. I do expect longs to be greatly rewarded, if they are correct!
Let’s start with the imatinib hypothesis, which is the parent drug that has since spawned varying takes on the thesis in GOSS, AVTE, and now IKT. This data is interesting because it has yet to be replicated with any other TKI so many years later. The imatinib Ph3 publication is available here. The 6MWD data is stat sig positive, as you can see below:
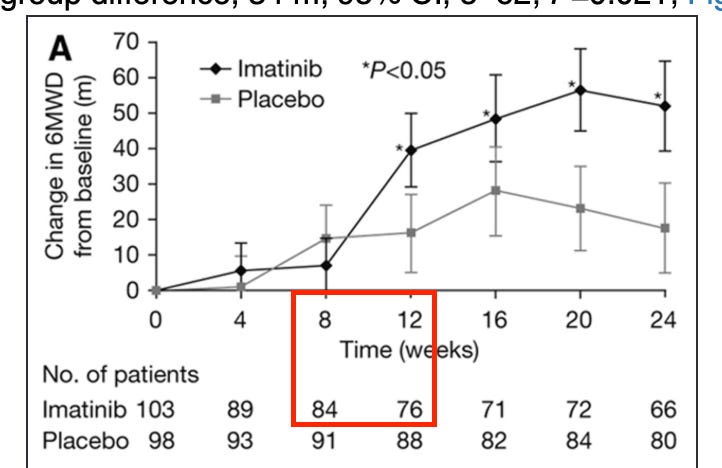
However, the dropouts here are controversial. The largest jump in benefit also includes the 2nd most dropouts of any period, and the most dropouts after the first 4 weeks. The stats for the trial remain positive even when conducting various sensitivity analyses to account for the dropouts, which is a positive:
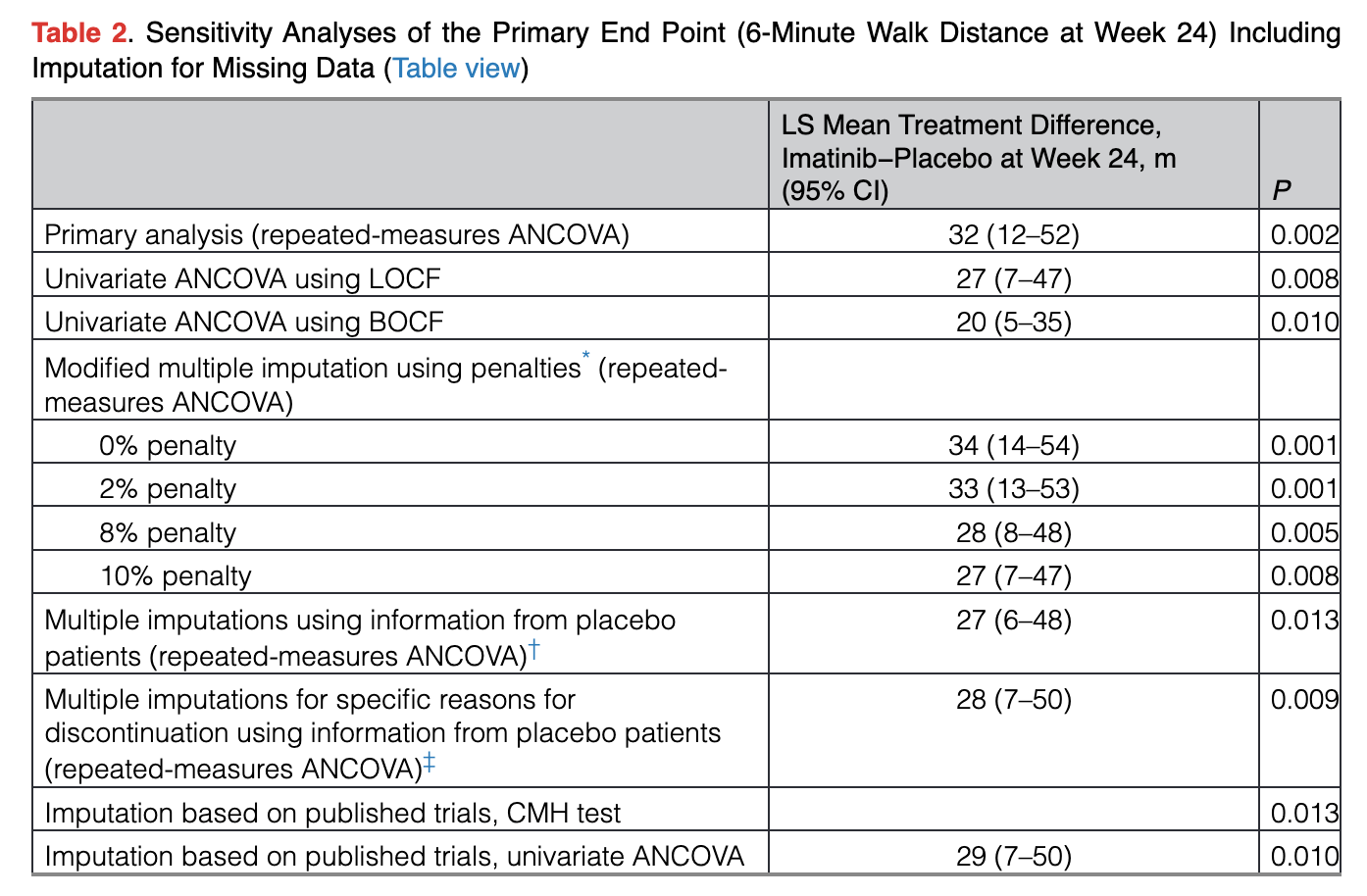
That being said, this is almost a 40% dropout rate by the end of the trial! I think it’s absolutely possible that this data is simply selecting for patients seeing an outlier benefit. This was never commercialized in part because the safety profile of the drug is horrid, so it’s quite reasonable that those seeing little to no benefit would drop out. By the time you get to that first impressive time point at week 12, around a quarter of the drug arm has already dropped out!
Some of the only data considering the entire population shows no separation at all vs. placebo:
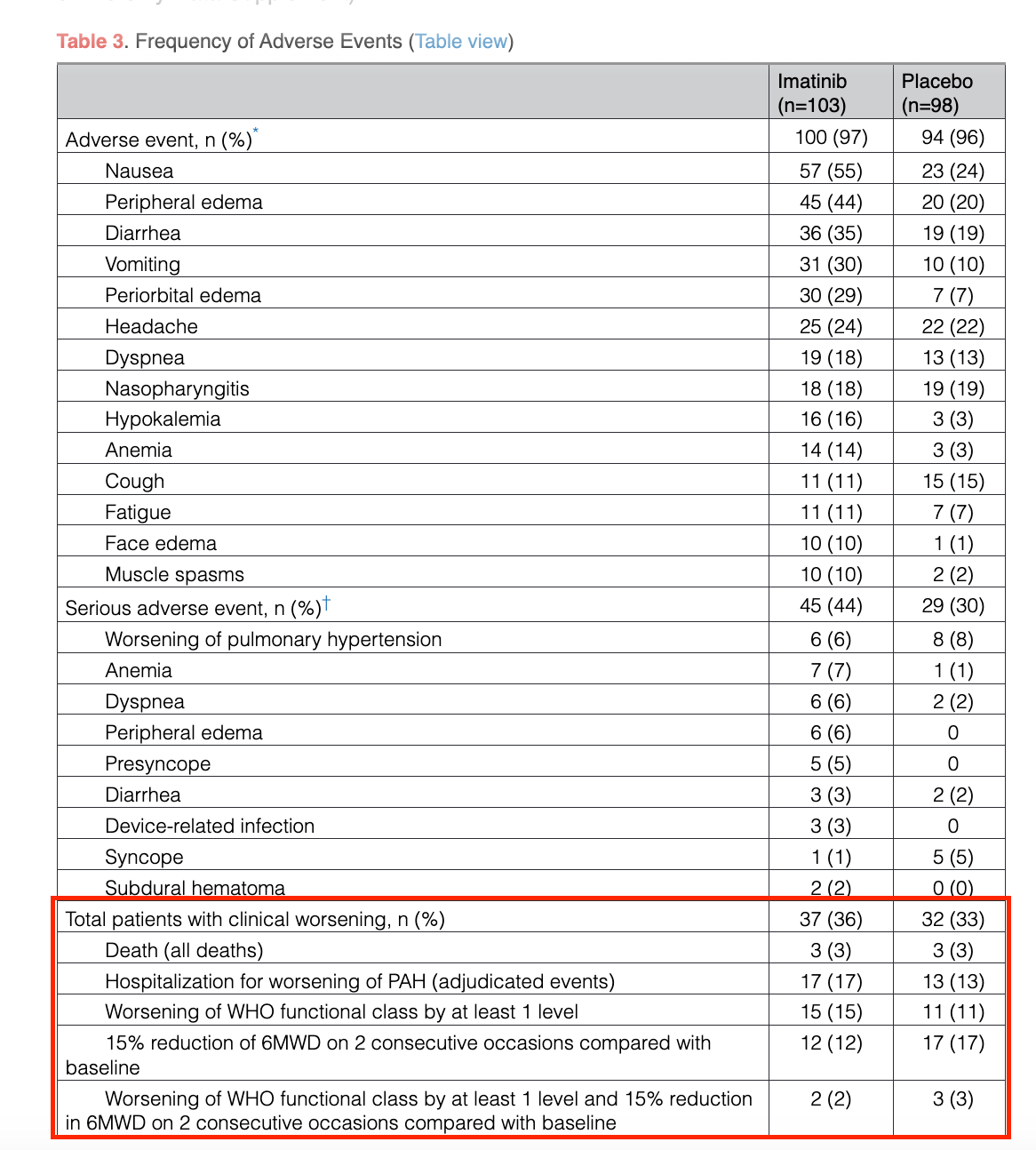
I’m sure the safety profile doesn’t help with clinical worsening to some extent, but I think seeing no separation at all, and even numerically worse data on drug in some cases, is still alarming.
Some of the backdrop here for the drug not being commercialized in PAH includes the safety/regulatory case, as well as the relatively short remaining patent life of the drug. I think an understated component of the issue here could be the dropouts, and lack of support on some of the secondary endpoints. Dropout bias driving this efficacy data would be one alternative explanation for why other TKIs never worked, why AVTE never worked, why it’s still yet to be replicated successfully in another form so many years later. Sure, maybe AVTE is an isolated event proving that crushed-up imatinib doesn’t work. I think it’d be foolish to rule out that systemic concentrations may be required for efficacy, though. In any event, I think it’s worth considering that the key hypothesis to this entire space isn’t quite as cut and dry as it’s made out to be.
Sotatercept, for reference, clearly separates on a number of similar measures:
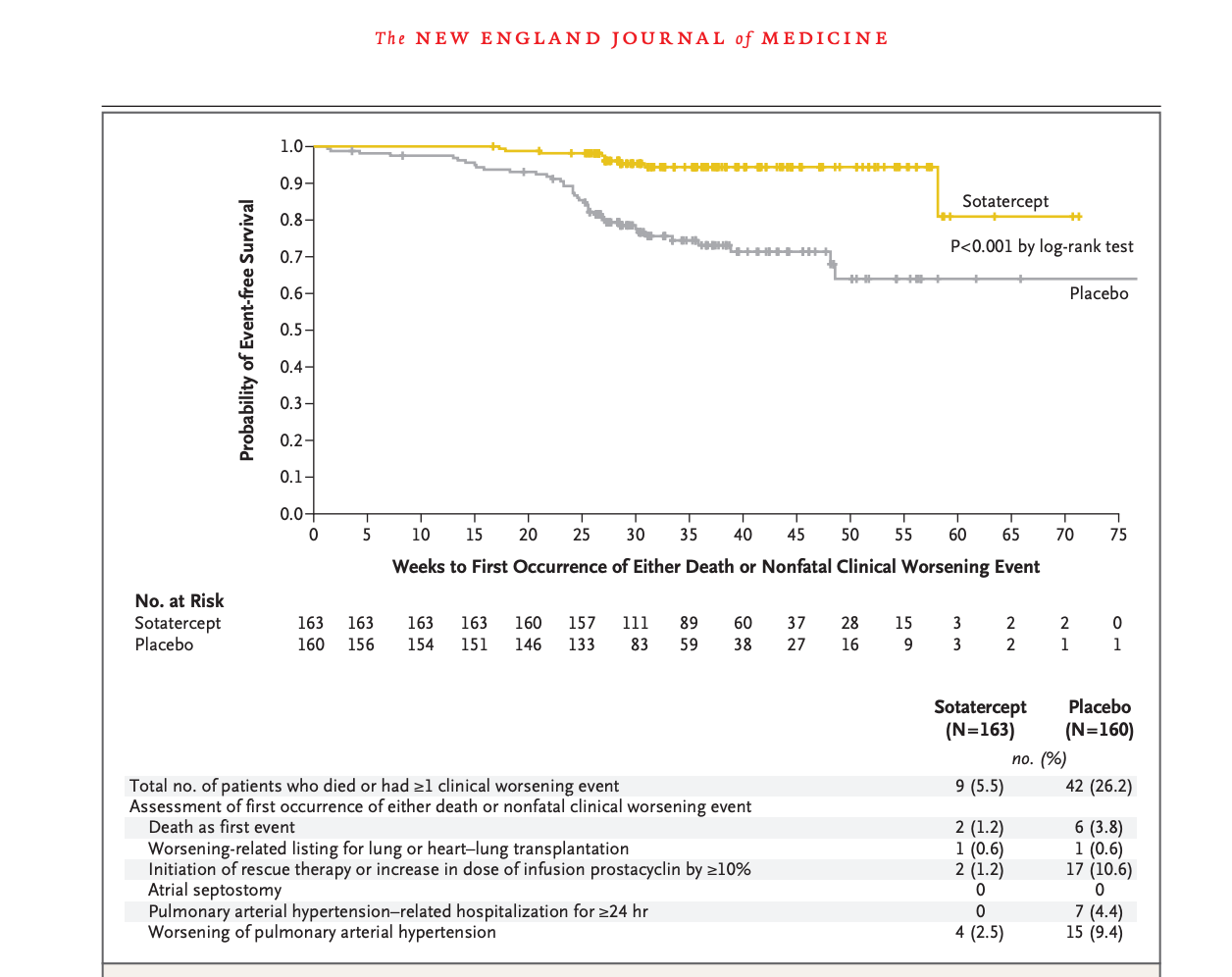
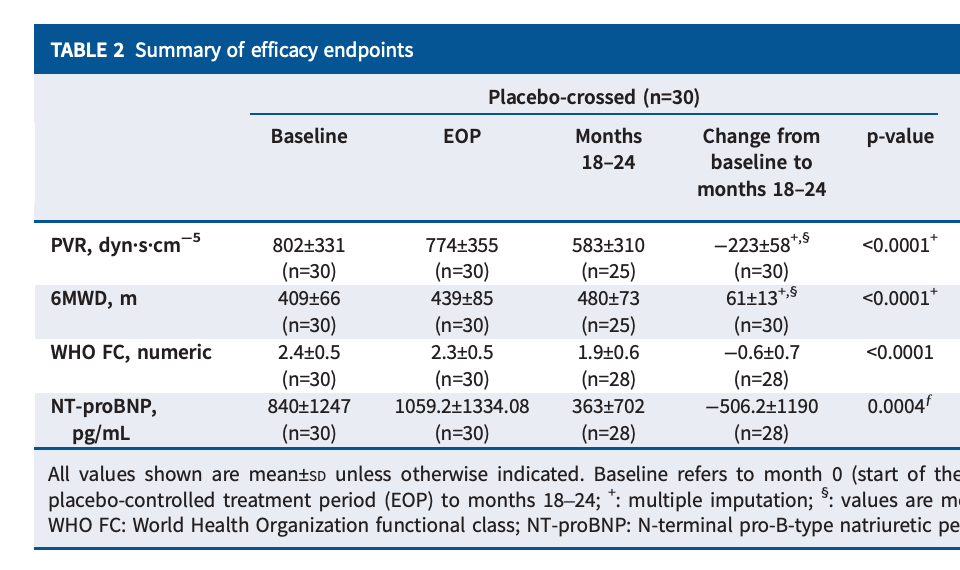
A handful of folks over the years now have tried their own spin on the imatinib hypothesis through dosing modifications, design changes, changing the form of delivery, or even using a different drug. The latter two of which are the approach GOSS took with seralutinib, a different TKI, which is inhaled. This first slide is a pretty good summary of their ph2 efficacy data:
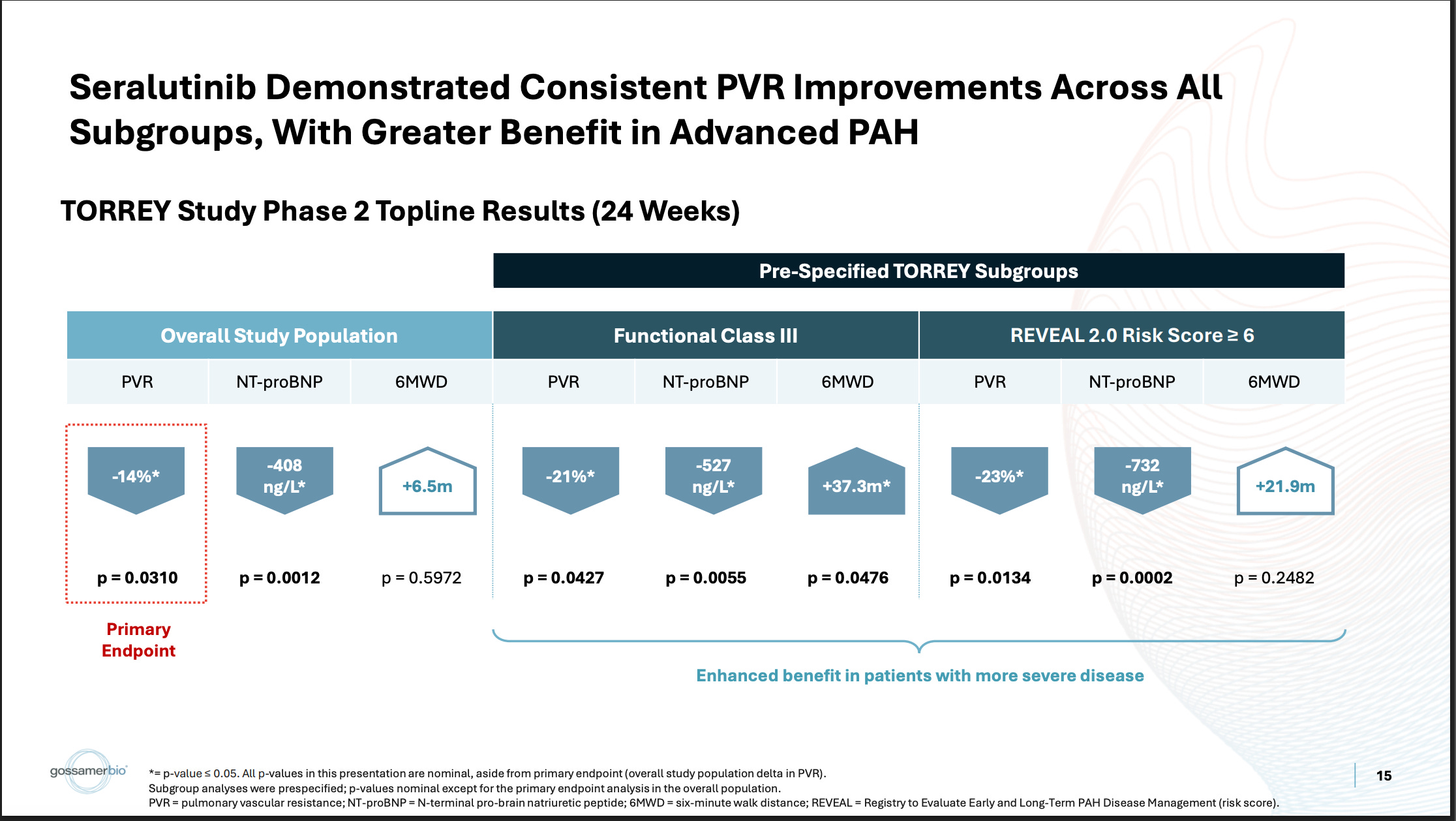
They ran a placebo-controlled study, which showed a stat-sig reduction on the PVR biomarker, with very little 6MWD functional benefit. In the more severe WHO Class III population, they show a deeper PVR reduction and better 6MWD benefit. Generally, the bar for these drugs on PVR (well-established biomarker) is more like -20% in the pooled population, so despite being stat-sig, the market considered that endpoint to be underwhelming as well. The stock got pummeled on this data, indicating the market didn’t care much for this subgroup analysis, but it’s been the subject of increased interest and debate recently. GOSS has definitely gotten the visibility to tell their story lately. Some parts of this story make sense to me, others I do have some concerns about.
First, this certainly is an imbalance in WHO Class between arms, no issues with that.
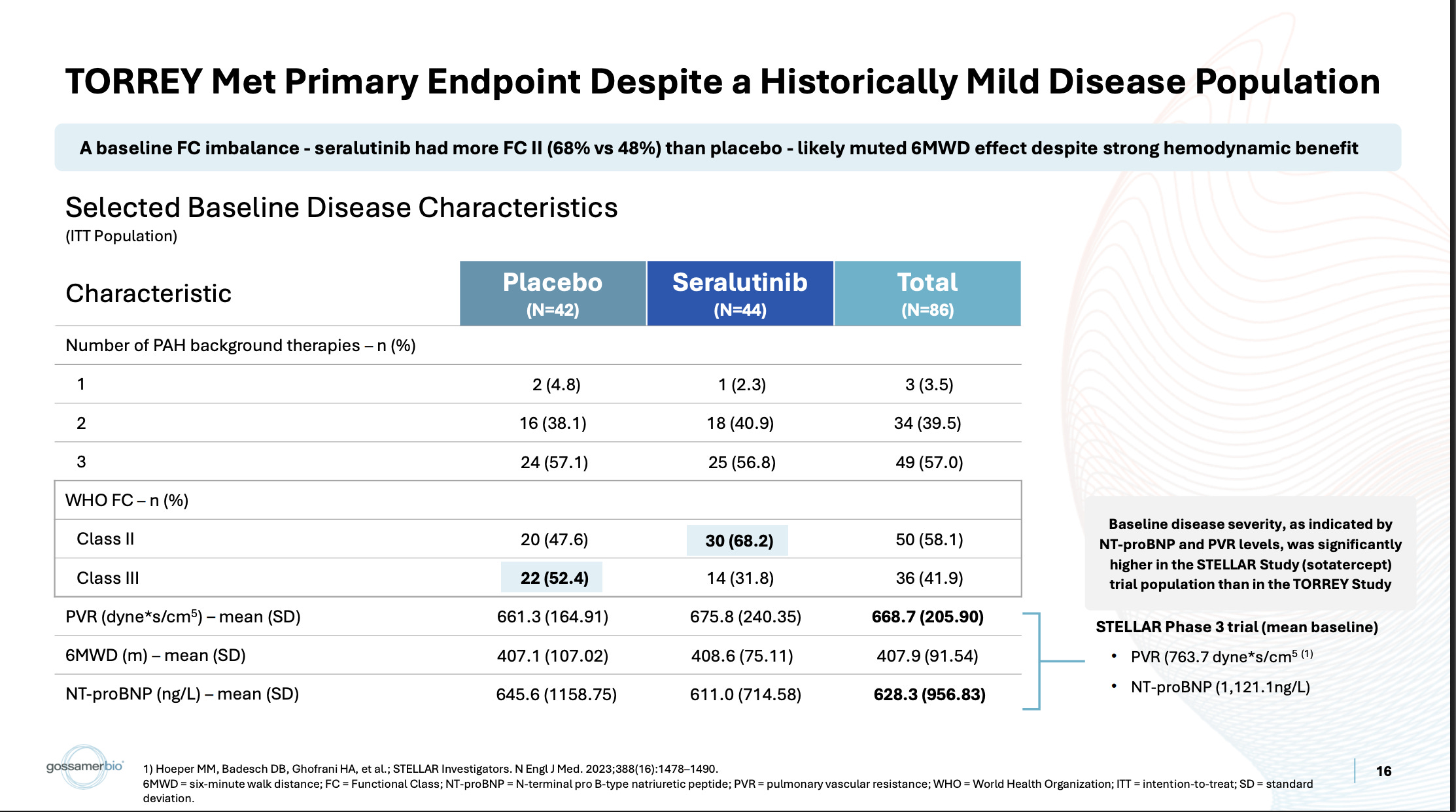
Other trials run recently did have higher PVR baselines, like the STELLAR trial they cite for example. Also true. One of the reasons some are more inclined to believe this subgroup than usual is that the imatinib Ph2 data also shows a similar bias toward more severe patients:
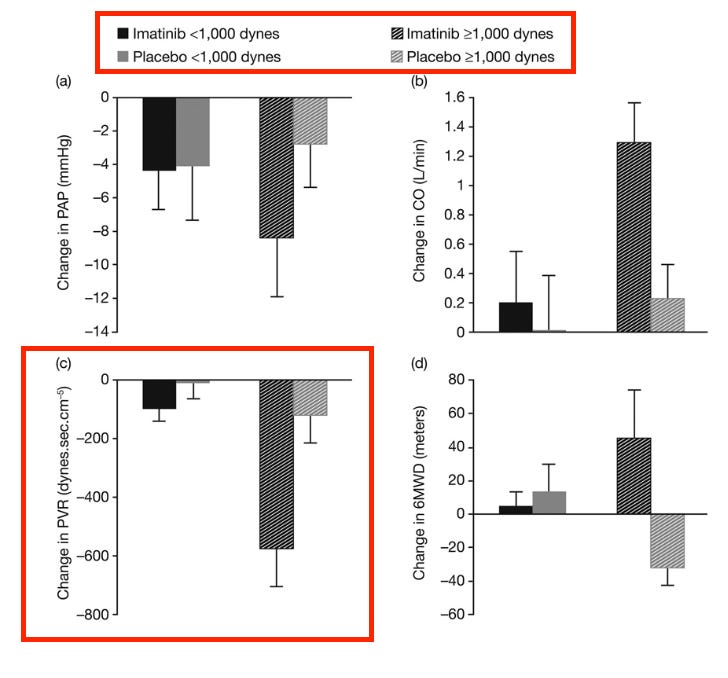
My issues with this is that the data in patients with <1000 dynes is quite problematic, and those are the patients who primarily exist today, even when targeting a more severe population. The mean baseline dynes in the seralutinib ph2 was ~650, and other comps would be more like ~750. Even with targeting more severe patients, I expect the vast majority of patients will still have PVRs <1000. Additionally, as an illustrative example, I’m not sure how much sense this makes. An 1100 dyne patient gets on imatinib, he might expect to end with 500-600 dynes based on this data. A 900 dyne patient might only expect to get to 800 dynes. This isn’t simply showing a weaker % effect size in milder patients, it looks they’re not getting to the same point numerically either. In order to believe this same problem exists today, you must believe that seralutinib maintains this same issue, but has ideally somehow walked the problematic threshold down slightly to be in line with the modern treatment paradigm. Additionally, this imatinib data was hamstrung by a meaningful baseline imbalance in the trial:
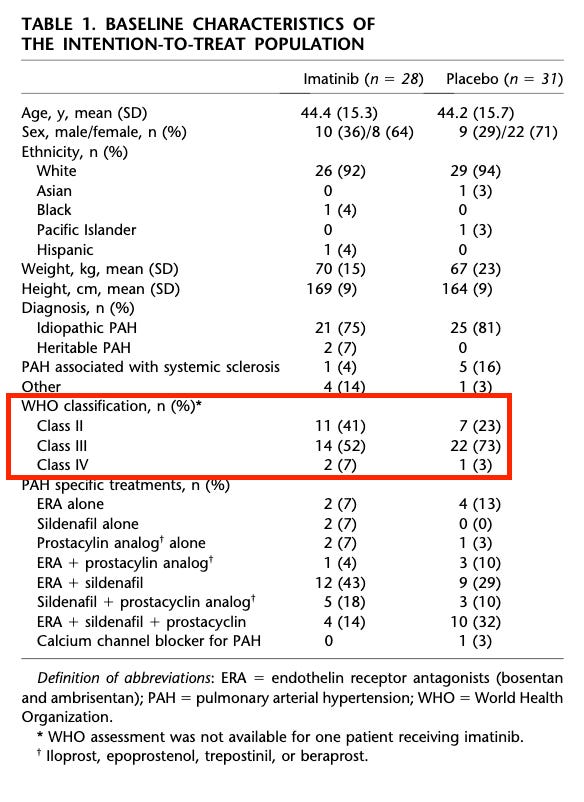
Not to the extent seen today, I will concede, but it’s still worth noting that this did not prevent them from showing more intriguing POC. The other important thing here is that the imatinib data establishes this separation in effect by stratifying by PVR. The seralutinib data shows this using WHO class. I find this interesting because the PVR stratification is in the TORREY pub, and it’s very underwhelming:
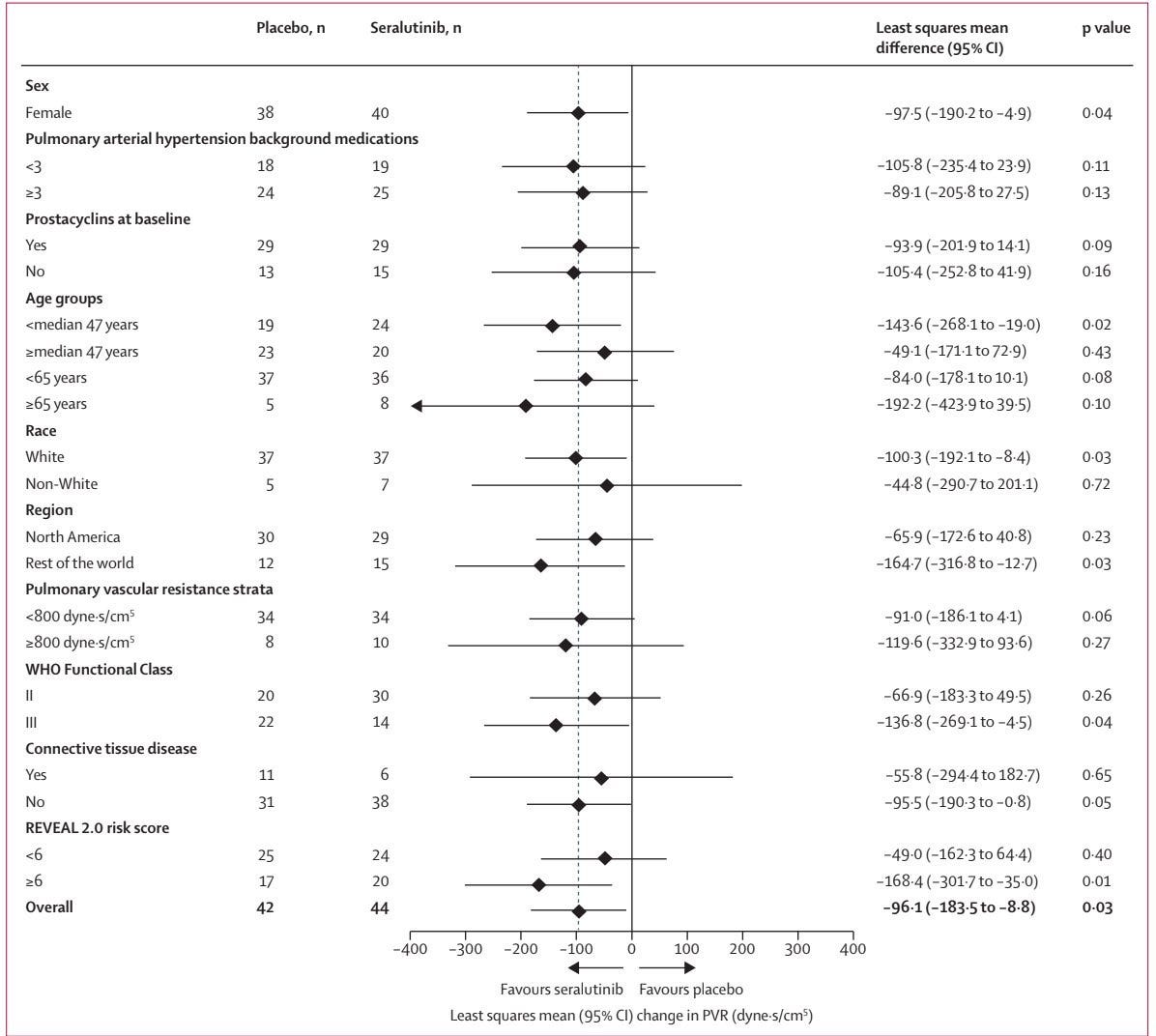
There’s a <30 dyne difference in effect size. I’m sure folks will caution against interpreting an n=10 treatment arm sample here, but it’s also worth noting that the class III subgroup is only an n=14 treatment arm! I’m also not sure of the rationale for an 800 dyne cutoff. As previously mentioned, imatinib’s cutoff was 1000. Obviously, that cutoff wouldn’t show anything of note, but I think it’s important that this cutoff doesn’t either. Whether this is because the entire treatment paradigm is too mild now, or if it’s because effect size isn’t quite as dependent on severity as some believe, either explanation is plausible, and both are problematic.
In the imatinib ph3 supplement, they do show some data using WHO class, but there’s a similar mean PVR reduction from baseline across both class II and III patients:
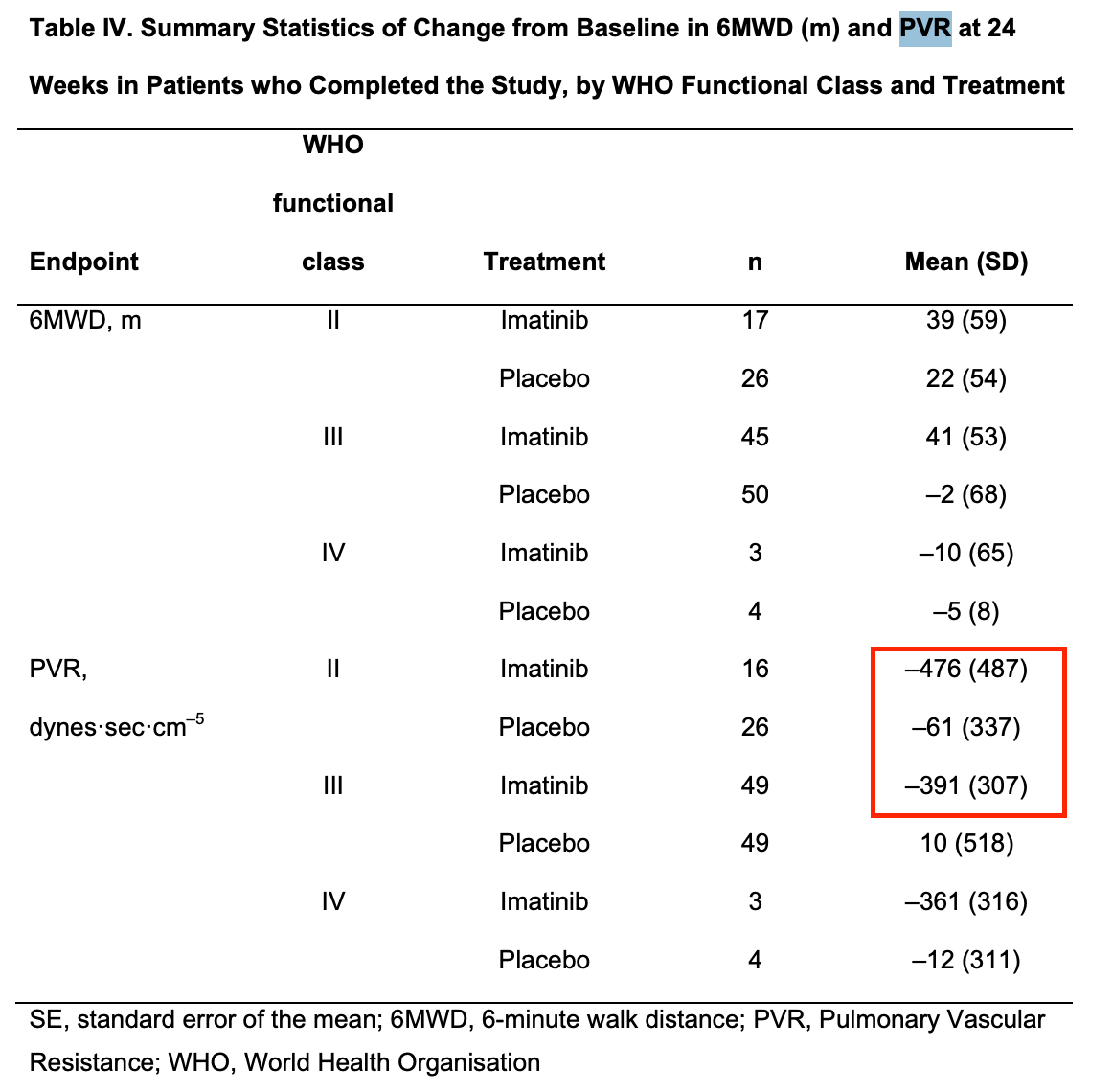
My key issue with the data is that there was already another opportunity to establish that the drug works best in severe patients, and yet it very much did not. While it is true that the placebo arm was stacked with class III patients, thankfully there was an OLE crossover, which most of that placebo arm joined.
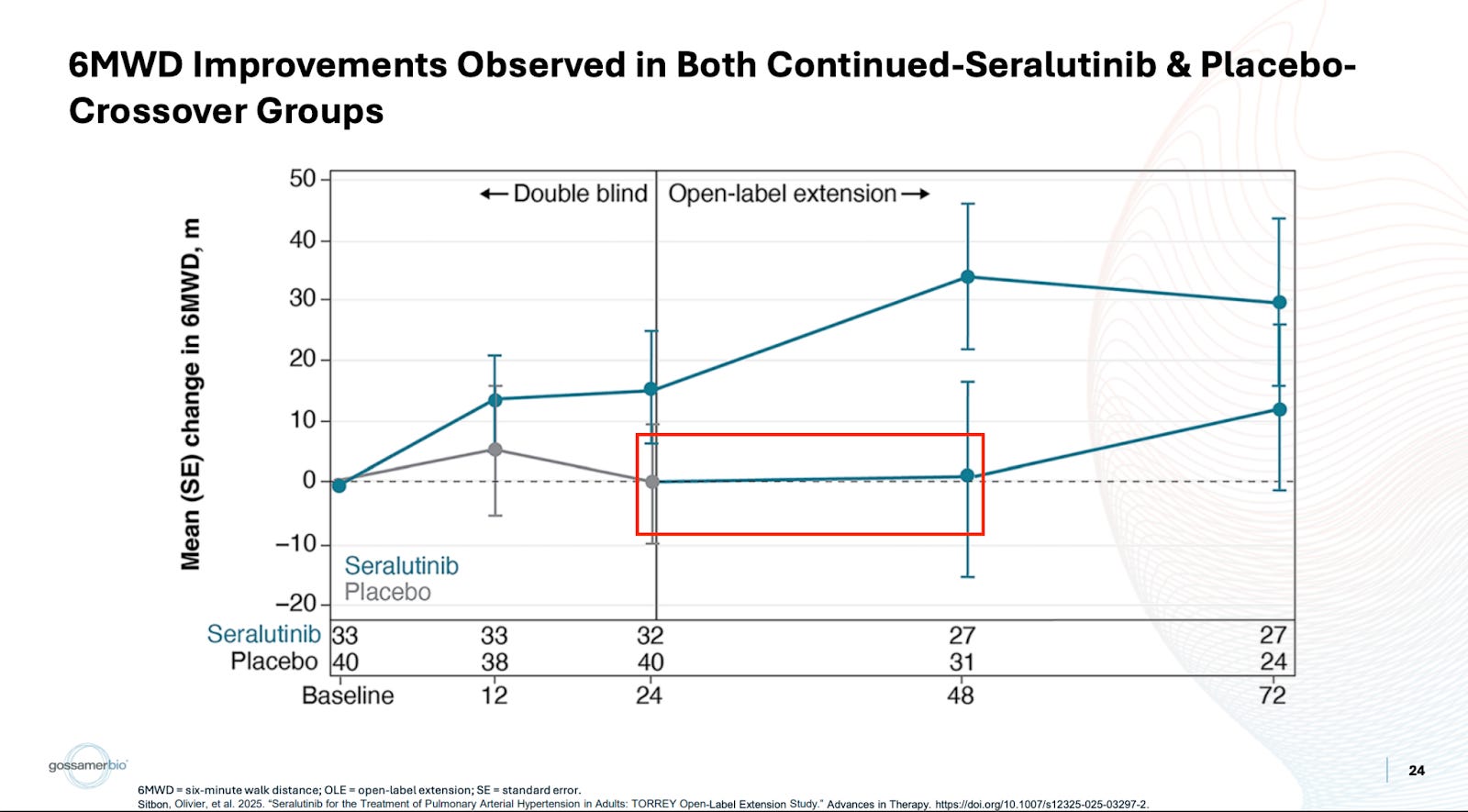
They crossed over three-quarters of the placebo arm, and then those patients saw 1 meter or so of benefit. The discussion around this tends to be targeted more toward the patients not catching up. In my eyes, this is completely irrelevant. They shouldn’t catch up, given the argument for treatment effect continuing to deepen beyond week 24. I think it’s a bit disingenuous to assume this is where people are setting the bar though. I would’ve simply liked to see the more sizable benefit we’ve been told to expect over 24 weeks in a more severe population. Instead, not only is this not any better, it’s substantially worse. Patients see around a single meter or so of benefit. Forgive some of the transcription as it’s from a free source, but I don’t find the argument convincing:
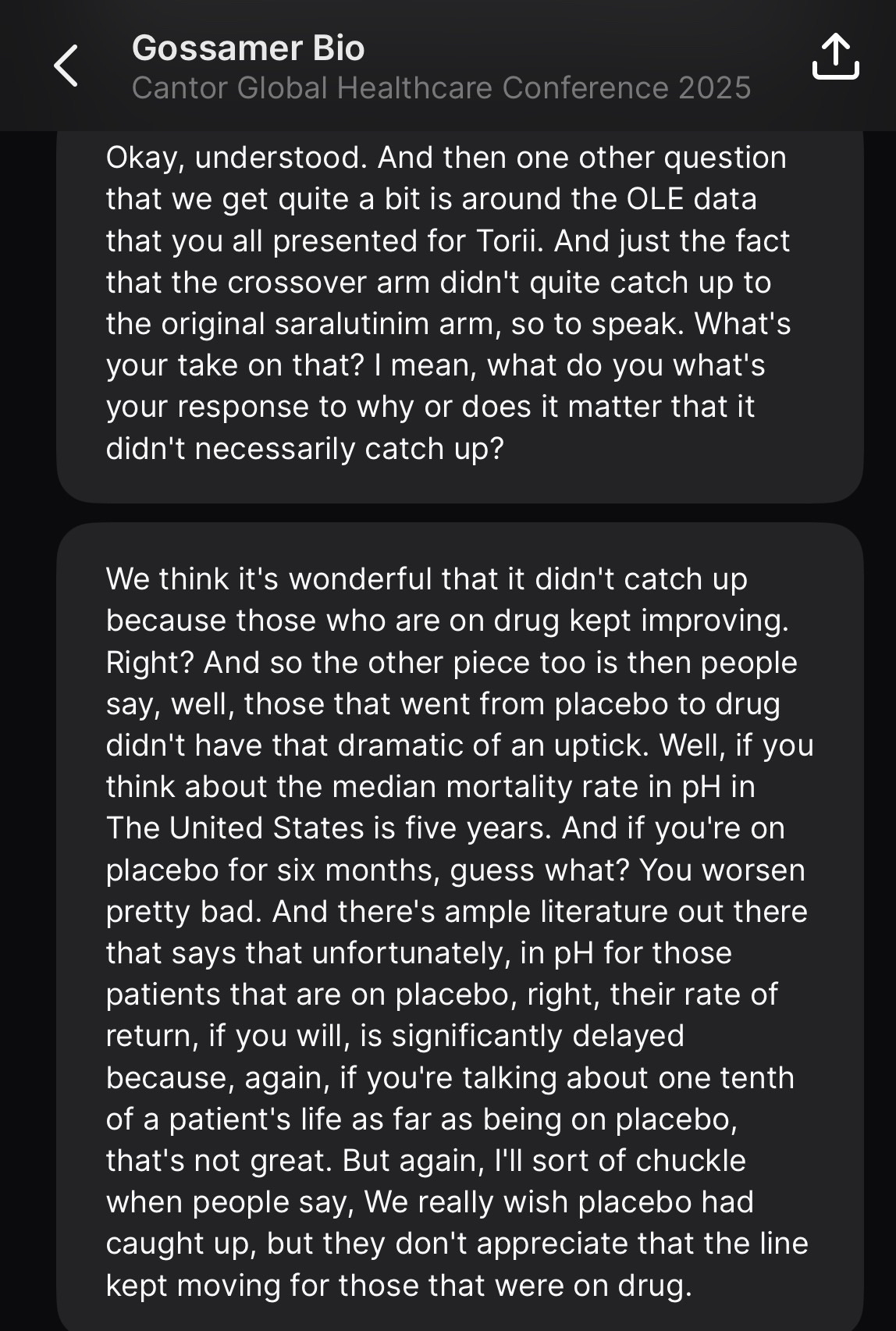
Again, I think positioning the perceived bar for this data as “needing to catch up to treatment arm” does not mesh with reality. Additionally, if spending more time on placebo makes it more challenging to treat patients, doesn’t this produce a number of follow-up questions? This trial needs to target an exact sweetspot of patients who are more severe, and not mild patients, since the drug doesn’t work well for them. But if these patients are too severe, apparently that’s also a problem because of what we see in the OLE data. The trial criteria can be found here, but it doesn’t appear to me that the duration of disease is a criterion. That would seem important to me given the takeaway from the OLE data. If 6 months on placebo made these more severe patients untreatable, is there a risk of some severe patients deteriorating quickly in the early weeks of the study?
Meanwhile, the Sota OLE crossover arm (with an ~800 PVR baseline and a healthy mix of FC II and III patients), performs like Sota! I don’t think the conversation around these patients should have anything to do with whether they “caught up to drug arm” or not, but rather that it’s notable these patients were treatable despite being on placebo for 24 weeks.
Sure, these patients have a higher baseline PVR, but this oscillation between whether this is more important or WHO class seems to fall to whichever is more convenient at the time.
The last thing I wonder about is the claim that 6MWD was confounded by covid. This is surely true to an extent. What I wonder about is why it still seems to correlate quite well with PVR reductions, if the quality control issues were so severe? The correlation between PVR and 6MWD is quite well established at this point, which is why PVR is so relied upon. If you refer back to the main ph2 efficacy data, what you see is what you’d expect to see from a reliable 6MWD dataset:
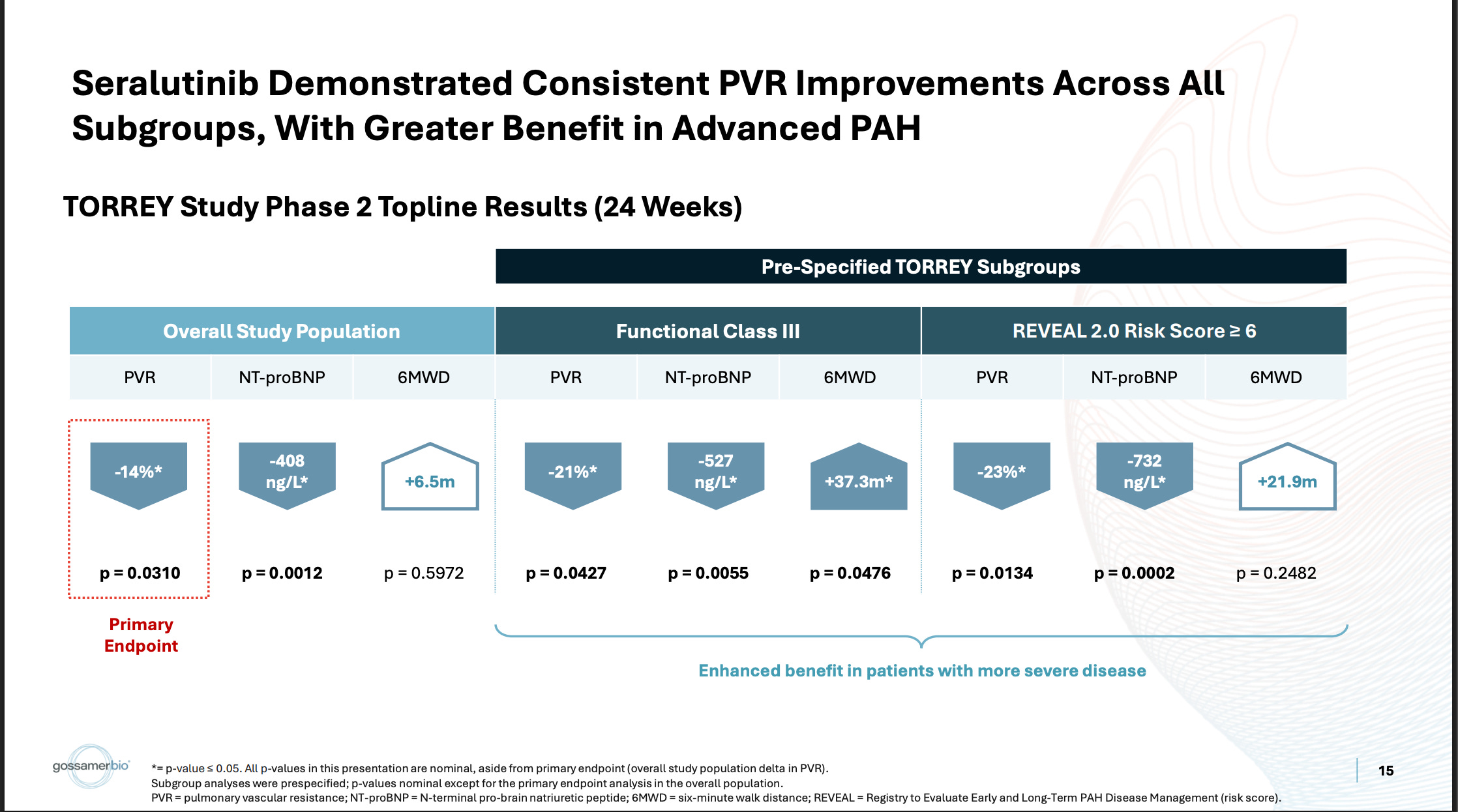
The pooled population has a relatively middling PVR value, which correlates with a relatively middling 6MWD value. The subgroups have better PVR values, which correlate with better 6MWD improvements. This makes sense. That’s what you’d expect to happen. Then, referring to the open-label data, you see the same thing:
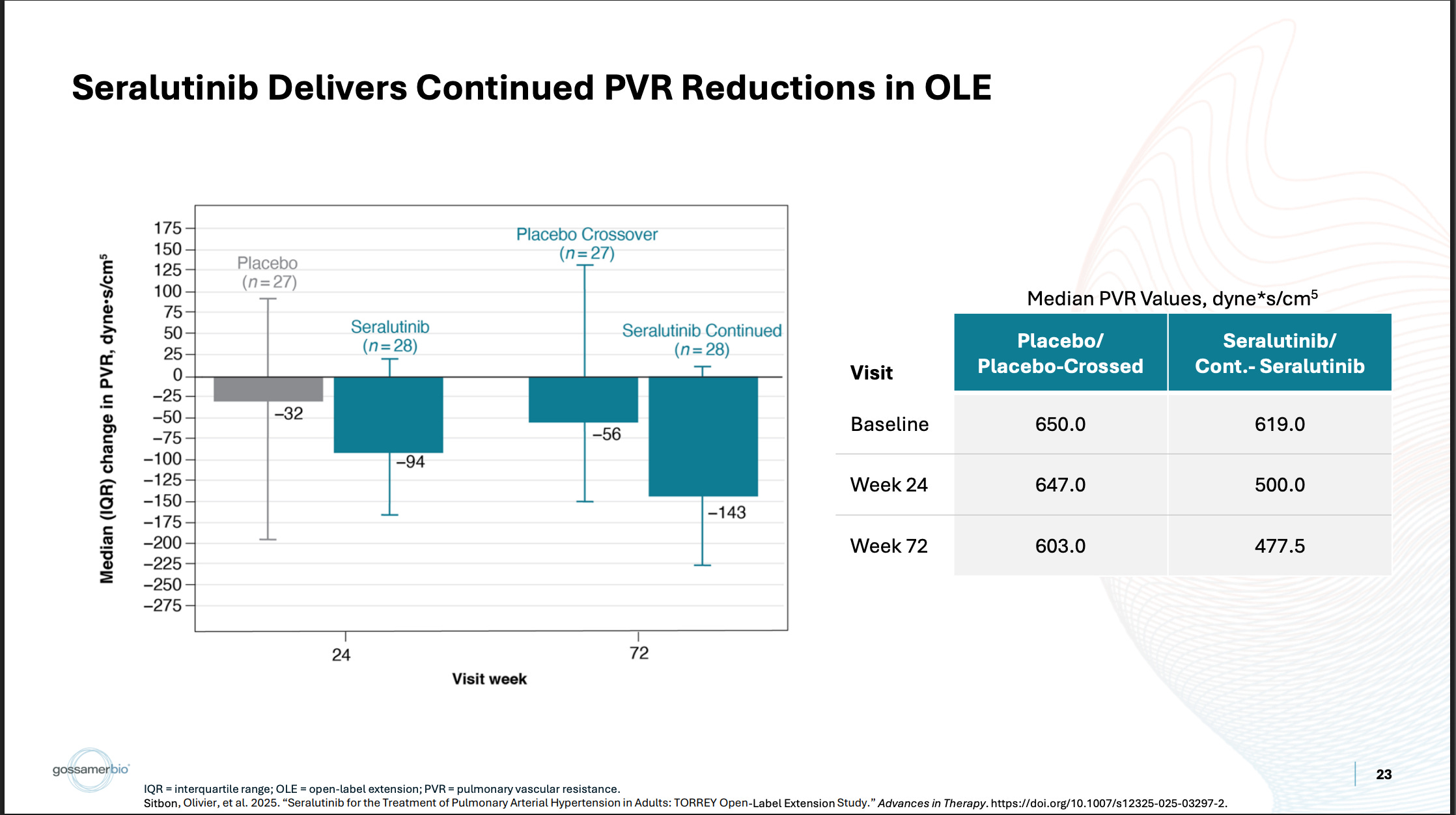
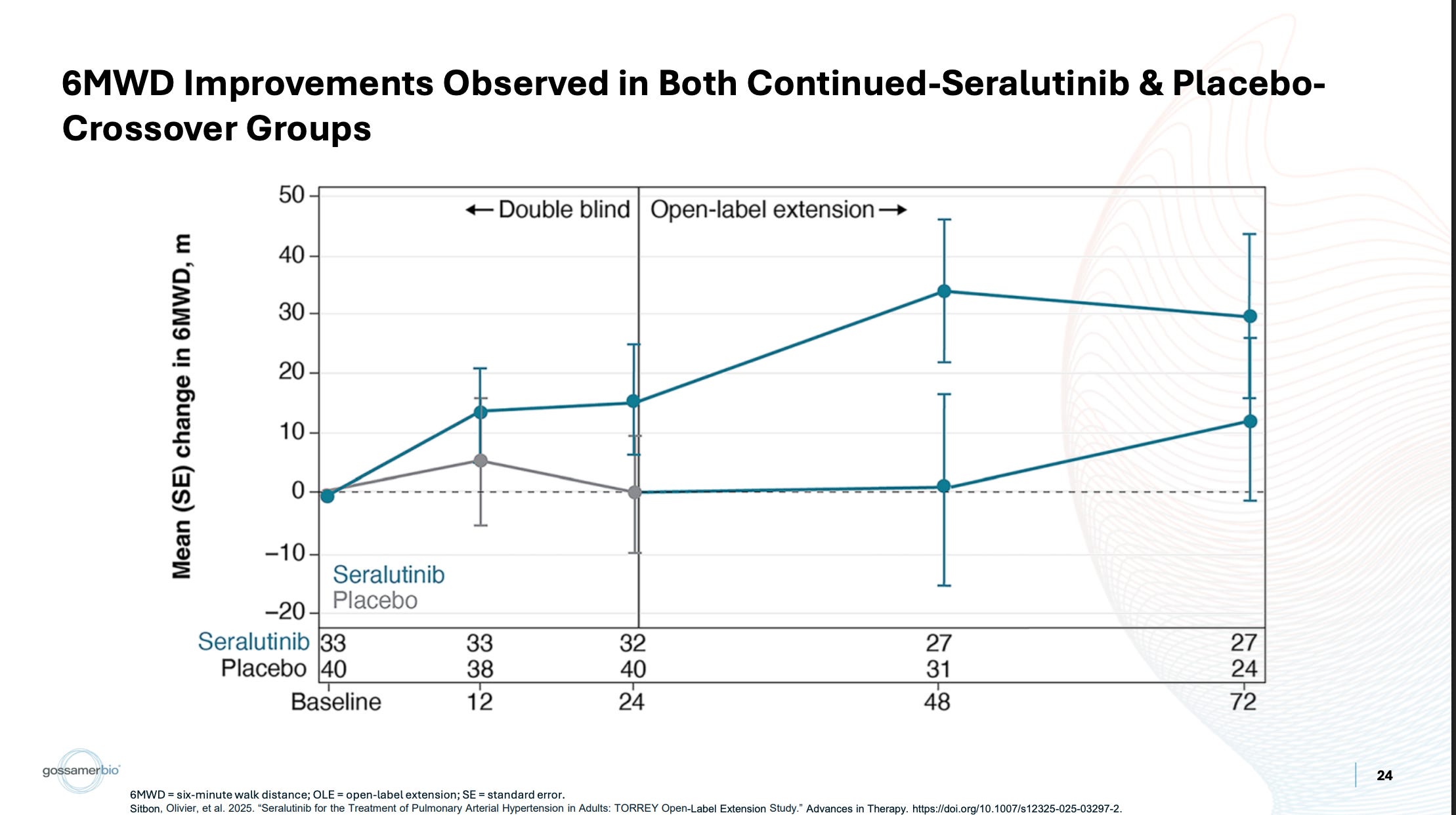
The placebo-crossed PVR underwhelms, and so does the corresponding 6MWD. The continued seralutinib data looks better, and so does the corresponding data. In my eyes, that’s not how I’d expect a heavily compromised 6MWD endpoint to behave. Even in small n subgroups and the OLE, it still correlates reasonably well with the biomarker. If there were severe QC issues in the dataset to the point that this data shouldn’t be relied upon… what are the odds that it would still correlate with PVR like that? I don’t really know what to make of this, because there are other verifiable examples of covid causing problems with 6MWT trials, but it’s confusing to me if nothing else.
I guess to close on this, my broader view here is that there’s a lot of different stories that go into why the existing data looks the way that it looks. Maybe they can thread the needle, all of these things individually are true and reasonable, and the half of the drug they still own is worth something like $8+. I don’t think a couple of these angles hold up to relatively basic push back, which is why I lean fairly skeptical. I do think it’s a really well-designed trial. If it does work I certainly see the use case, and the week 48 data as potential differentiation is a nice touch. We’ll find out sometime this month I suppose, and I’m looking forward to it!